Introduction
The evolution of Large Language Models (LLMs) has ushered in a transformative era in scientific discovery, positioning them as powerful tools for streamlining research, from idea generation to verification and publication writing. This study evaluates large language models (LLMs) in generating code from algorithm descriptions from recent NLP papers. The task requires two key competencies: (1) algorithm comprehension: synthesizing information from papers and academic literature to understand implementation logic, and (2) coding expertise: identifying dependencies and correctly implementing necessary APIs. To facilitate rigorous evaluation, we introduce SciReplicate-Bench, a benchmark of 100 tasks from 36 NLP papers published in 2024, featuring detailed annotations and comprehensive test cases. To assess algorithm understanding, we introduce reasoning graph accuracy, which quantifies similarity between generated and reference reasoning graphs derived from code comments and structure. For evaluating implementation quality, we employ execution accuracy, CodeBLEU, and repository dependency/API recall metrics.
Building on SciReplicate-Bench, we propose Sci-Reproducer, a multi-agent framework consisting of a Paper Agent that interprets algorithmic concepts from literature and a Code Agent that retrieves dependencies from repositories and implement solutions. In our experiments, we evaluate various powerful Non-Reasoning LLMs and Reasoning LLMs as foundational models. The best-performing LLM using Sci-Reproducer achieves only 39% execution accuracy, highlighting the benchmark's difficulty.
SciReplicate-Bench
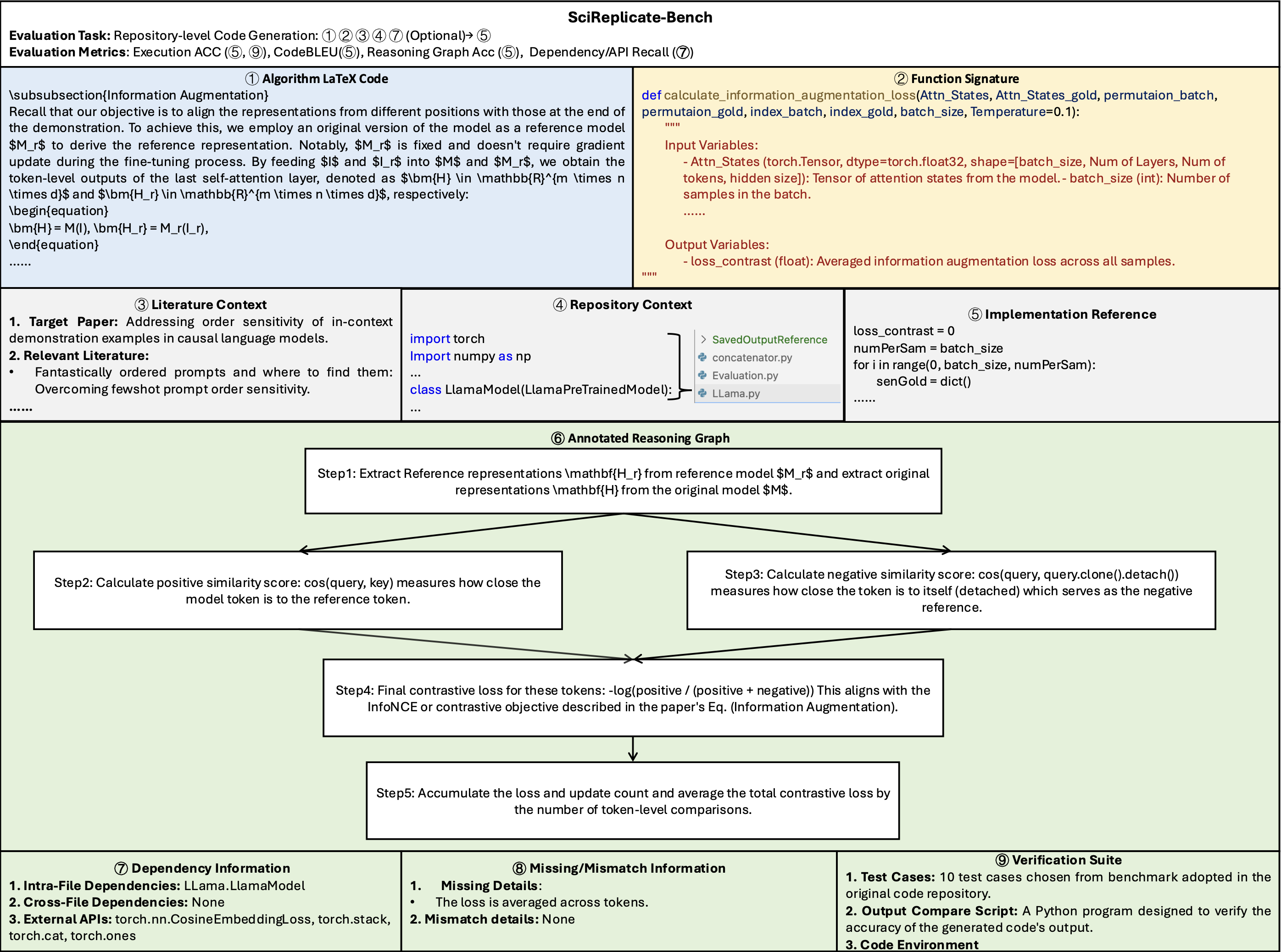
Figure 1: The overview of the SciReplicate-Bench.
Task Definition
The SciReplicate-Bench focuses on repository-level code generation, where each task is centered around implementing a specific function or class method. For code generation, the following components are provided as inputs to LLMs:
- Function signature: the definition of the target function, including detailed descriptions of its input and output variables.
- Algorithm LaTeX code: the LaTeX code description of the target algorithm, typically located within a subsection or paragraph of the target paper.
- Literature context: the original paper along with its cited references, providing broader conceptual context.
- Repository context: all source files and code in the repository that inform or support the target implementation.
Metrics
- Reasoning Graph Accuracy: it evaluate how well LLMs understand the logic and implementation of algorithms.
- Execution Accuracy: we integrate the generated code into the repository and execute it to obtain results. If all test cases match the reference results, we consider the code correct.
- CodeBLEU: it evaluates how similar the generated code is to reference code by using the traditional BLEU metric while incorporating syntactic information through abstract syntax trees (AST) and semantic understanding via data-flow graphs (DFG).
- Recall: it refers to the recall scores targeting intra-file dependencies, cross-file dependencies, and external APIs.
Sci-Reproducer
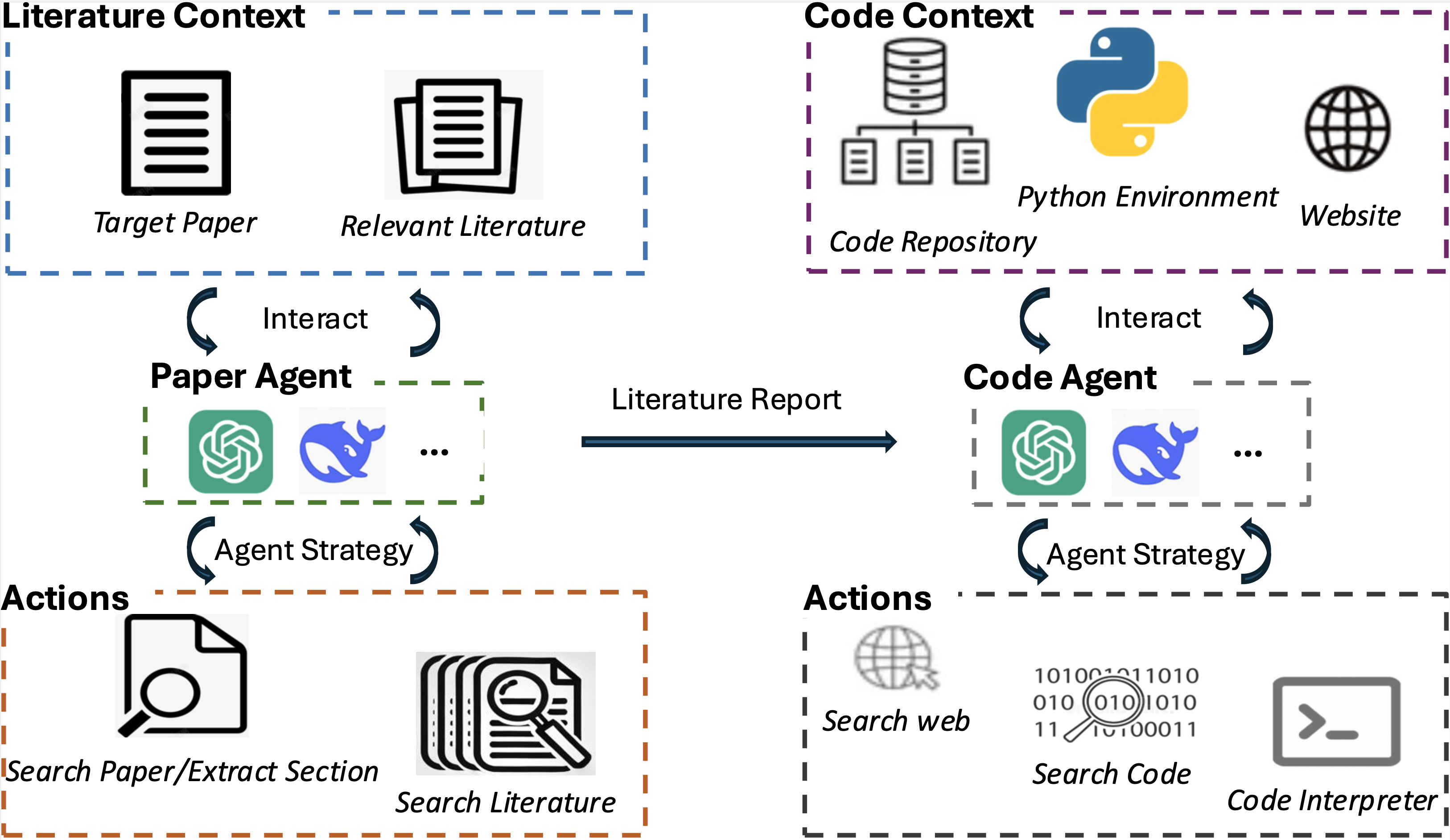
Figure 2: The overview of the Sci-Reproducer.
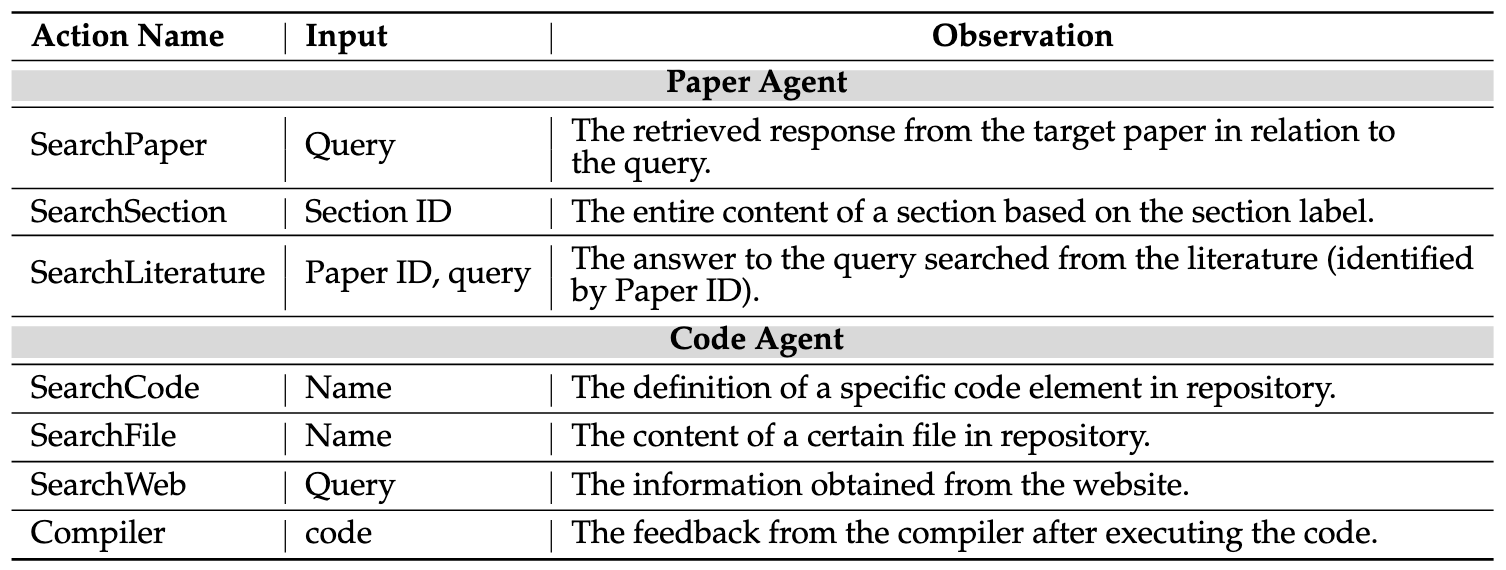
Table 1: The pre-defined actions for the Paper Agent and the Code Agent.
To address this task, we introduce Sci-Reproducer, a dual-agent framework designed for scientific paper methodology replication. As illustrated in Figure 2, Sci-Reproducer comprises a Paper Agent and a Code Agent that collaboratively work to replicate algorithms described in a given paper. Both agents follow the ReAct strategy, and their predefined actions are outlined in Table 1.
Paper Agent
The Paper Agent incrementally builds an understanding of the target algorithm by executing predefined actions to query the literature context. After concluding that all necessary information has been collected, it generates a comprehensive report comprising key findings that fill in the missing components of the target algorithm's LaTeX source.
Code Agent
The Code Agent integrates the target algorithm's LaTeX code with the Paper Agent's report to comprehensively understand the algorithm. It leverages actions to search the code repository for necessary dependencies that aid implementation. The agent can also browse websites for additional information and use a compiler to test and iteratively debug the code, ensuring proper execution by identifying and fixing syntax errors.
Video: Demo of the Sci-Reproducer framework.
Experimental Results
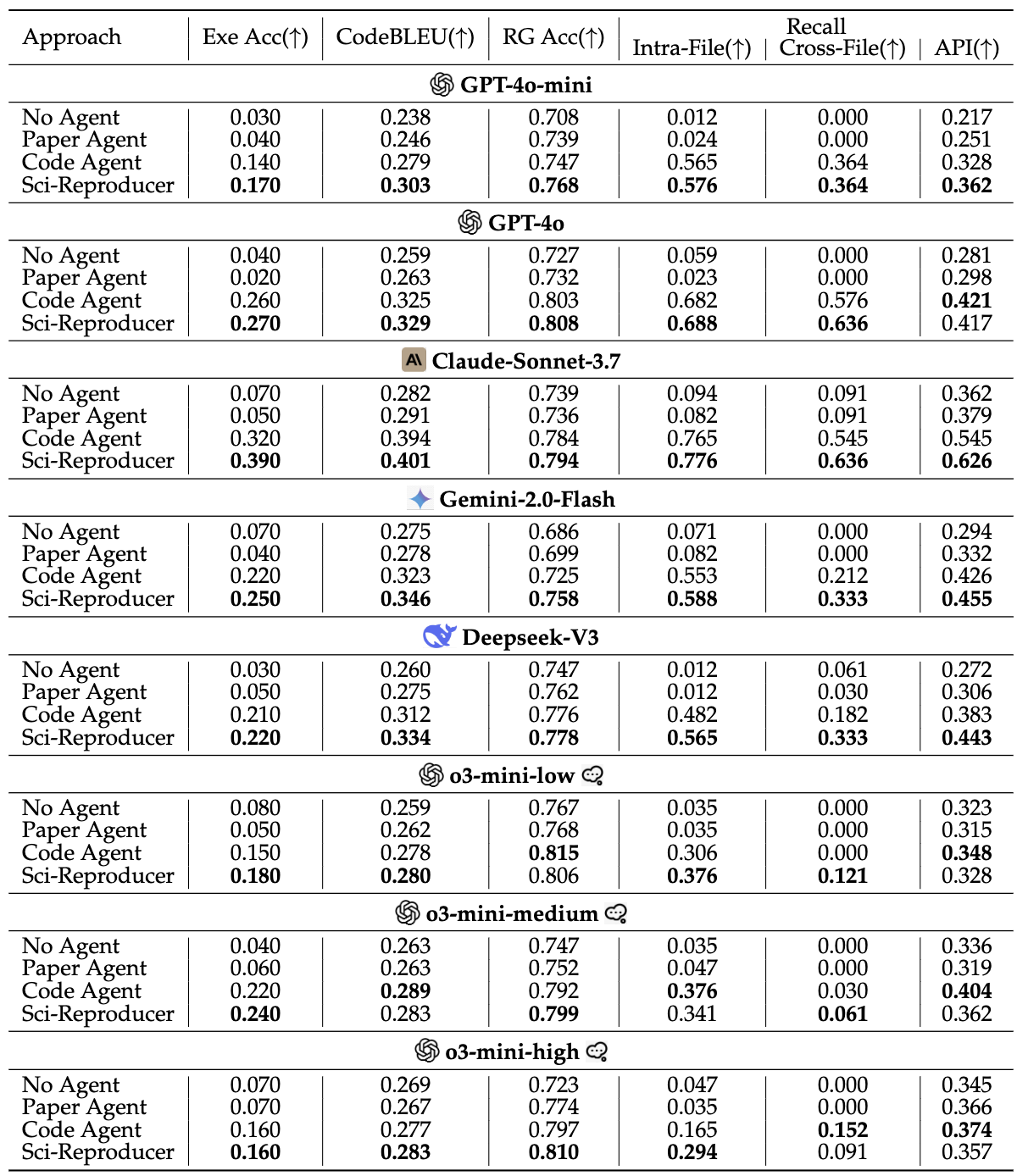
Table 2: Performance evaluation on the SciReplicate-Bench. "Exe Acc" represents execution accuracy while "RG Acc" indicates reasoning graph accuracy.
Table 2 displays Sci-Reproducer’s evaluation results and contributions of code/paper agent. The results offer the following key insights:
- LLMs struggles on SciReplicate-Bench: most LLMs perform poorly, even the best-performing model, Claude-Sonnet-3.7, only achieved 0.390 execution accuracy.
- LLMs can comprehend algorithm logic: most models are capable of understanding the core implementation logic of target algorithms (indicated by reasoning graph accuracy), even without any external assistance, with an average score of 0.731 in the ``No Agent'' setting.
- LLMs face challenges with actual implementation: although LLMs are capable of understanding algorithms, their performance in code generation remains suboptimal.
- Accurate dependency and API identification is crucial for code implementation: effectively recognizing and leveraging dependencies from the source repository and external APIs is essential for accurate code implementation.
Tool Usage Analysis
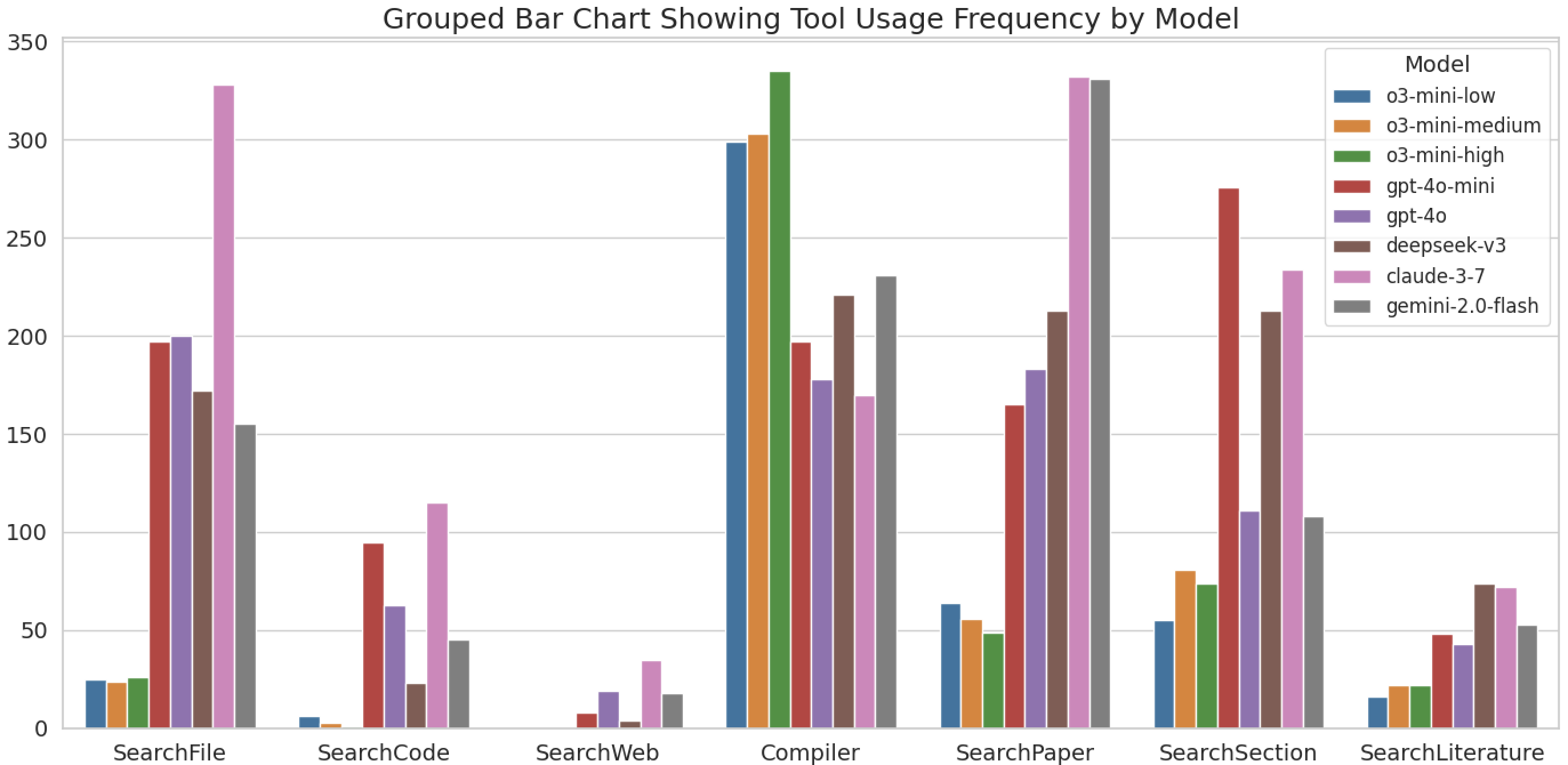
Table 3: A grouped bar chart illustrating the frequency of tool usage by different models. The x-axis represents various actions, while the y-axis indicates the total number of times each tool was used on this dataset.
Reasnoning LLMs tend to overthinking which leads to limited improvement: As shown in Table 3, reasoning LLMs tend to rely more on internal deliberation rather than retrieving external information. Regarding code-related actions, reasoning LLMs use “SearchFile”, “SearchCodeItem”, and “SearchWeb” an average of 25.0, 3.3, and 0.0 times, respectively. In comparison, non-reasoning LLMs use these actions significantly more often, with averages of 210.4, 68.2, and 16.8 times, respectively. Such over-reliance on internal reasoning hurts their overall performance: the execution accuracy of models such as o3-mini-high and o3-mini-low is comparable to that of gpt-4o-mini, despite their theoretical advantages.
Error Analysis
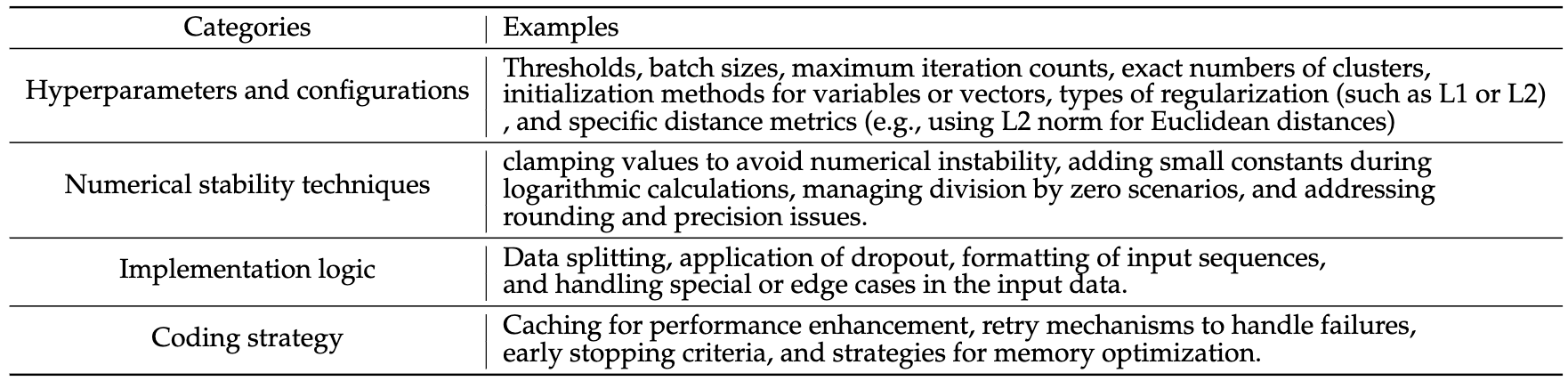
Table 4: Some examples for different missing information categories.
- Syntax Errors: syntax errors mainly result from incorrectly using repository dependencies.
- Logic Errors: another issue stems from differences in implementation logic, which can be broadly categorized into: (1) discrepancy in algorithm implementation that result in differing outputs, and (2) missing or mismatch information in the algorithm descriptions in the paper compared to the actual code, and the details can be found in Table 4.
Reference
Please check our paper and dataset for details. If you find our work helpful, please consider citing it using the following:
@article{xiang2025scireplicate,
title={SciReplicate-Bench: Benchmarking LLMs in Agent-driven Algorithmic Reproduction from Research Papers},
author={Xiang, Yanzheng and Yan, Hanqi and Ouyang, Shuyin and Gui, Lin and He, Yulan},
journal={arXiv preprint arXiv:2504.00255},
year={2025}
}For questions and comments, please contact Yanzheng Xiang at: yanzheng.xiang[AT]kcl.ac.uk


